一、前言

为什么要研究这篇内容:
每天都在和浏览器打交道
一道面试题
开拓视野
通过了解一个url的请求发生了什么来了解现代Web服务架构的演进,这里的每一个环节深挖下去都是一个很大的方向,所以这里仅做一个简介,不会深挖每个环节。
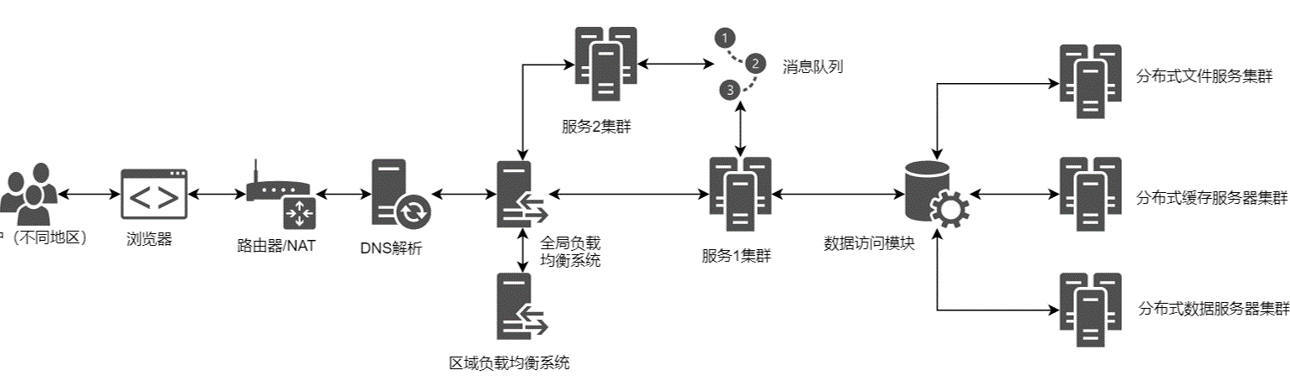
二、现代Web服务架构的演进
1. 基础的样子
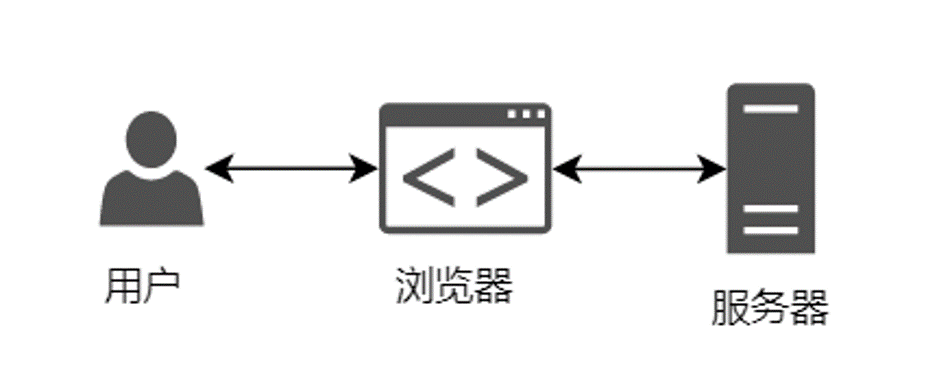
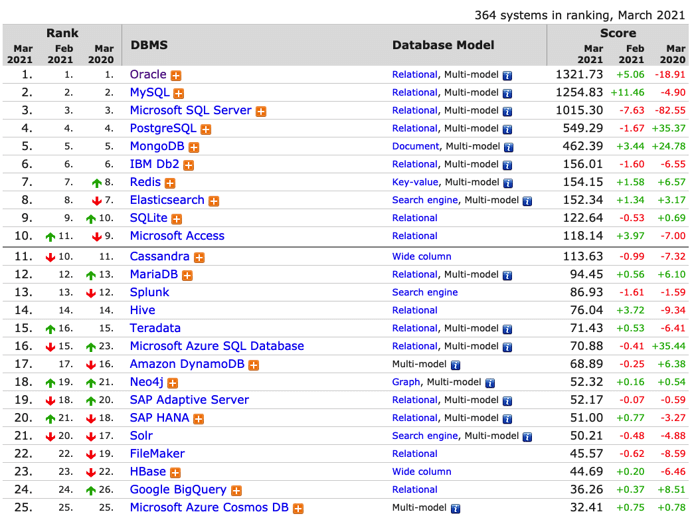
用户通过在浏览器输入IP,访问通过存放在服务器中的HTML。
这时候就会有两个问题:
浏览器和服务器如何进行通信?
客户的内网IP怎么和公网IP进行通信?
(1) 浏览器和服务器如何进行通信?
① TCP、UDP和HTTP
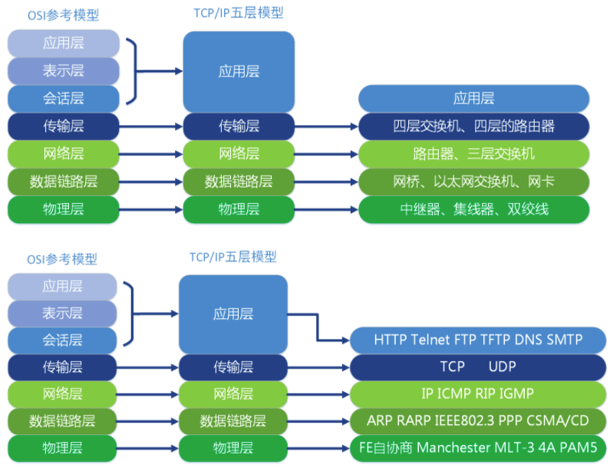
这三个关键词可以说是现代Web的基石,现在常说的前后端开发基本上基于的都是TCP、UDP和HTTP,在TCP/IP的五层模型中,TCP和UDP属于传输层,HTTP属于应用层,不是很严谨的说,HTTP基于TCP协议。
TCP:
- 面向连接(网络底层的数据传输),可靠,慢,资源占用多
- 三次握手,四次挥手
关于TCP的三次握手,有个很经典的笑话:
1 | 「嗯,我想听一个 TCP 的笑话。」 |
UDP:
- 无连接,不可靠,快,资源占用少
HTTP:
- 简单快速、灵活、无状态、无连接(应用层面的沟通交互)
② HTTP的简介
HTTP是浏览器中最常见的协议,基本上现在的所有页面都是基于该协议。
HTTP基于TCP,当然也继承了TCP的可靠性,当浏览器和服务器进行通信的时候,也会进行三次握手和四次挥手。
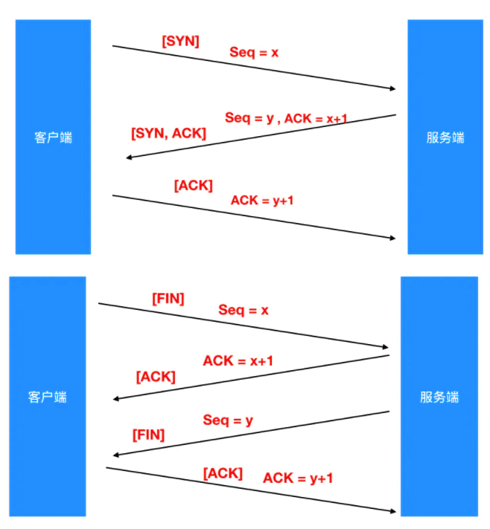
这个过程比较复杂,如果把女朋友当作客户端,把男朋友当作服务端,那么大概就是这个样子:
三次握手:
- 女朋友向程序员提出约会(Seq = x)的建议,然后女朋友进入SYN_SEND状态。
- 程序员收到后同意了去约会(ACK = x + 1), 然后向女朋友建议去吃麻辣烫吧(Seq = y),程序员进入SYN_RCVD状态。
- 女朋友收到建议后,勉为其难的答应了,然后告诉程序员说 那好吧(ACK = y + 1)。女朋友就进入了ESTABLISHED状态, 程序员也进入了 ESTABLISHED状态,整个约会讨论结束。
四次挥手:
- 女朋友向程序员提出分手
- 程序员告诉女朋友说,我知道了,但是要考虑一下
- 程序员考虑清楚后,跟女朋友说那就分手吧
- 女朋友接收到程序员的消息后,然后还在等程序员发挽留的消息,然而等了两天后没等到,就认为程序员是真的不会再发消息来了,于是就拉黑删除程序员,关闭连接了。
HTTP的版本特点:
- HTTP/0.9:无状态、只有GET
- HTTP/1.0:支持POST、增加头信息、增加二进制文件
- HTTP/1.1:Keep-Alive、管线化
- HTTP/2.0:多路复用、服务器推送
③ HTTPS的简介
当网络变得越来越普遍的时候,安全性就越来越重要,这时候HTTPS就出现了。HTTPS经由HTTP进行通信,但利用SSL/TLS来加密数据包。HTTPS开发的主要目的,是提供对网站服务器的身份认证,保护交换资料的隐私与完整性。
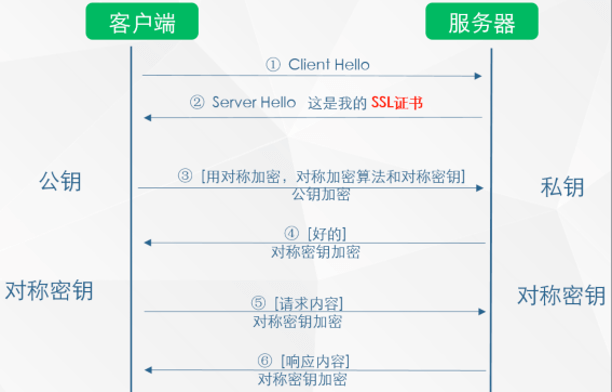
HTTPS的大致通信流程:
- 客户端发起一个http请求,连接到服务器的443端口
- 服务端把自己的信息以数字证书的形式返回给客户端
- 浏览器验证证书的合法性
- 生成随机密码(对称加密)
- 用服务器公钥加密后发送给服务器
④ 服务器
硬件更加可靠的能被其他终端访问的终端,管理资源并为用户提供服务,常见系统类型:
- GNU/Linux(Debian、RedHat、Arch)
- Windows Server
- MacOS Server
(2) 用户的内网IP怎么和公网IP进行通信?
当用户越来越多,多个用户可能在同一个局域网内,走同一个网络出口访问服务器。
这时候,用户设备使用的是内网IP,这时候他们如何和公网IP进行通信呢?
这就需要用到下面讲到的NAT技术。
2. NAT
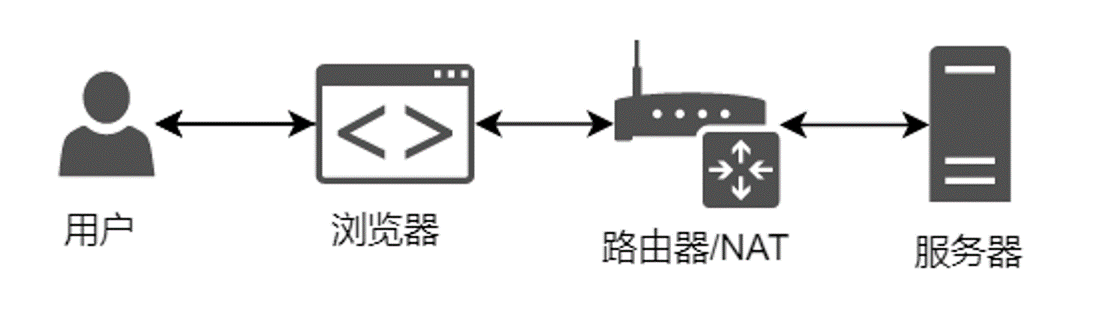
用户的请求会在路由器中通过NAT技术转换为公网请求,发送给服务器。这里也会有两个问题:
NAT是什么?
我们常用的是URL,怎么和IP关联起来?
(1) NAT是什么?
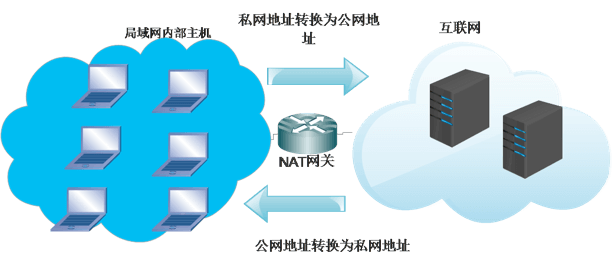
NAT(Network Address Translation),是指网络地址转换,NAT是用于在本地网络中使用私有地址,在连接互联网时转而使用全局 IP 地址的技术,旨在通过将一个外部 IP 地址和端口映射到更大的内部 IP 地址集来转换 IP 地址。 基本上,NAT 使用流量表将流量从一个外部(主机)IP 地址和端口号路由到与网络上的终结点关联的正确内部 IP 地址。
常见的NAT实现方式:
- 静态NAT(一对一)
- 动态NAT(多对多)
- NAT重载(PAT端口地址转换)
(2) 我们常用的是URL,怎么和IP关联起来?
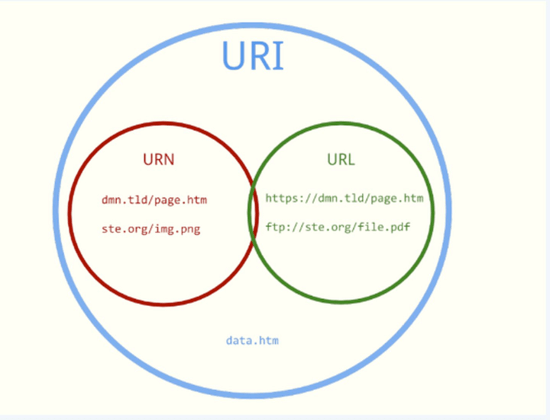
想要了解URL和IP的关联,首先先得了解下URI、URL、URN:
- URN (Uniform Resource Name, 统一资源名称):
- Ryan Shang
- ISBN 0-486-27557-4
- URL (Uniform Resource Locator,统一资源定位符):
- file:///home/username/RomeoAndJuliet.pdf
- Tel: //13800138000
- URI (Uniform Resource Identifier, 统一资源标识符)
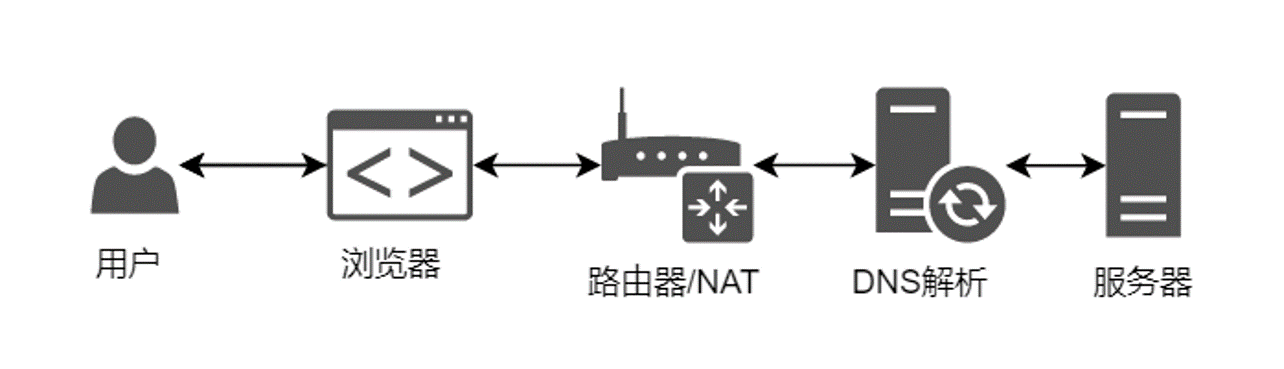
为了不让用户记住无规则的IP地址,让用户能使用URL来访问网站,出现了DNS服务来解决这个问题。
3. DNS
我们继续带着两个问题来学习:
- DNS是什么?
- 现阶段如何提高服务稳定性?
(1) DNS是什么?
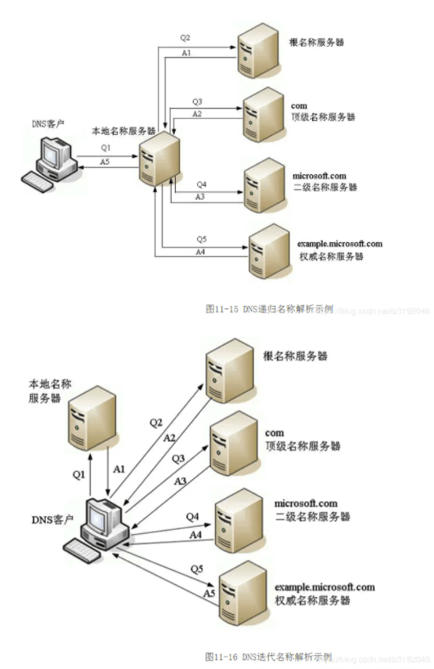
域名系统(英语:Domain Name System,缩写:DNS)是互联网的一项服务。它作为将域名和IP地址相互映射的一个分布式数据库,能够使人更方便地访问互联网。DNS使用TCP和UDP端口53。
(2) 现阶段如何提高服务稳定性?
当前阶段最简单有效的就是对功能进行拆分。
4. 服务器功能拆分
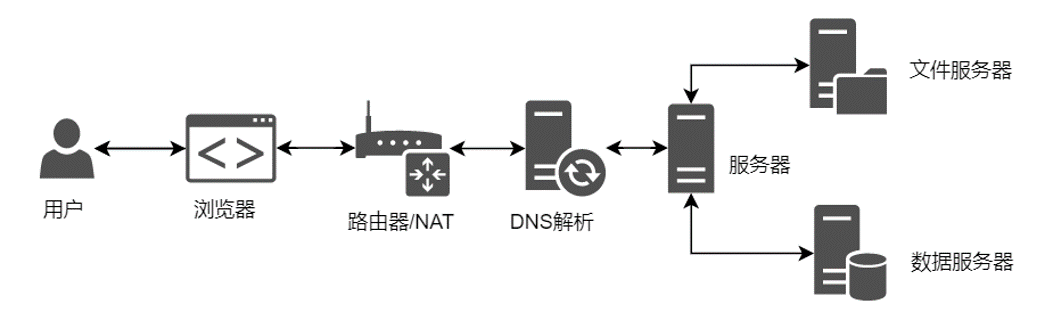
我们继续带着两个问题来学习:
- 数据库是什么?
- 现阶段如何提高服务的QPS?
(1) 数据库是什么?
数据库,简而言之就是存放数据的地方,用户可以对这些数据执行增删改查等操作。
常见的数据库类型有关系型数据库(SQL)和非关系型数据库(NoSQL)。
关系型(SQL):
- Oracle
- MySQL
- SQL Server
- Access
- PostgreSQL
- OceanBase
非关系型(NoSQL):
- 键值存储: Redis
- 列存储: HBase
- 面向文档: MongoDB
- 图形: Neo4J
- 搜索引擎: Solr
(2) 现阶段如何提高服务的QPS?
这个时候想要提高服务的QPS就要用到缓存机制了
5. 缓存
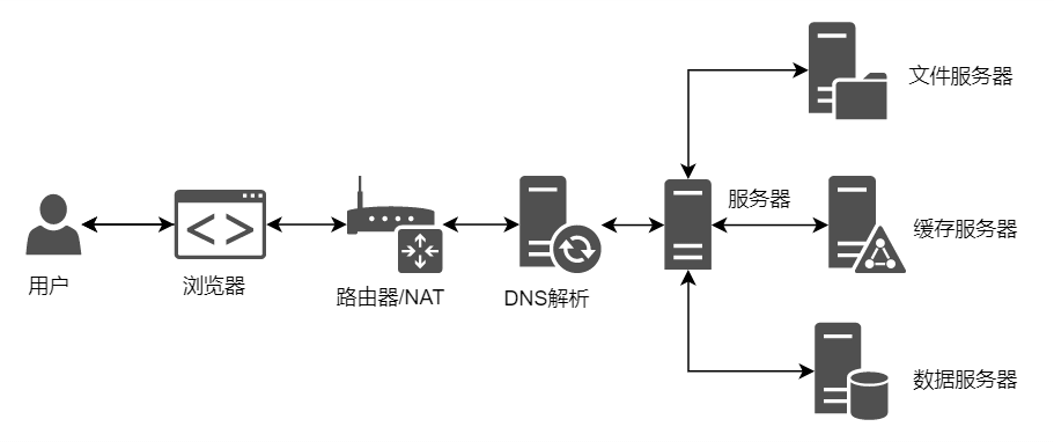
我们继续带着两个问题来学习:
- 常见的缓存方式?
- 现阶段如何提高服务的QPS?
(1) 常见的缓存方式
① Redis
Redis(Remote Dictionary Server)是一个使用ANSI C编写的开源、支持网络、基于内存、分布式、可选持久性的键值对存储数据库。一般情况下,MySQL的单机QPS在几千左右,而Redis的单个实例的QPS可以达到10W左右。
在一些业务场景下合理使用Redis可以大幅提高QPS。
这里再提下常见的Redis缓存问题:
- 缓存穿透(数据库和缓存中的无效查找)
- 缓存击穿(高并发请求同一个key刚好失效)
- 缓存雪崩(大规模缓存失效)
② 浏览器缓存
浏览器也有自己的缓存机制,主要分为强缓存和协商缓存:
强缓存(Expires、Cache-Control):不到过期时间都直接使用缓存资源。
协商缓存(Last-Modified & If-Modified-Since、Etag & If-None-Match),请求服务器获取资源上次更新时间,如果有更新则重新请求,如果没有更新则直接使用缓存资源。
(2) 现阶段如何提高服务的QPS?
这个阶段就可以考虑增加负载均衡机制,使用服务器集群。
6. 负载均衡
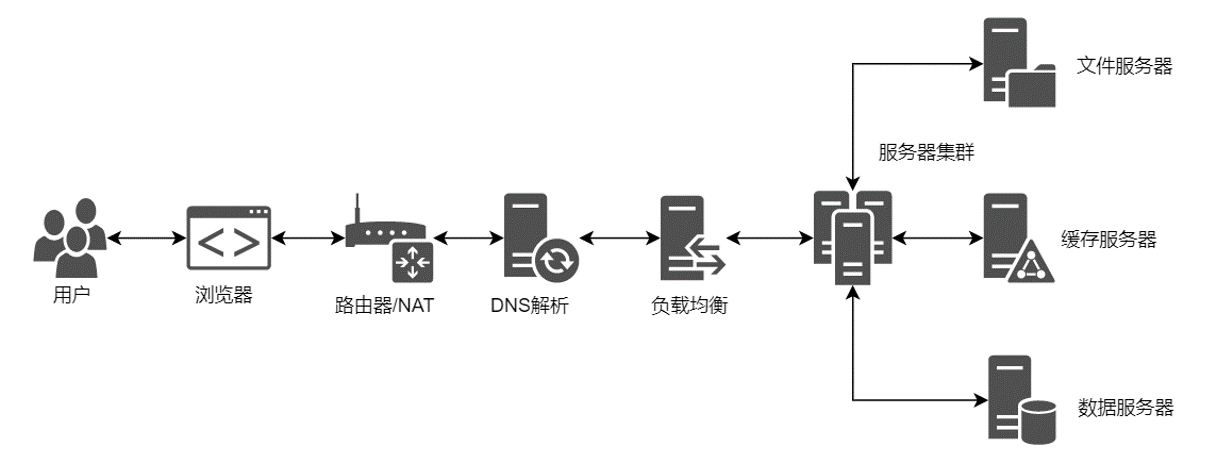
我们继续带着三个问题来学习:
- 什么是负载均衡?
- 正向代理和反向代理是什么?
- 现阶段如何提高服务的QPS?
(1) 什么是负载均衡?
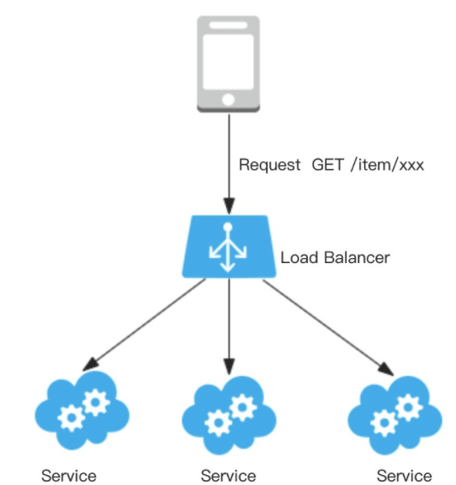
负载平衡(英语:load balancing)是一种电子计算机技术,用来在多个计算机(计算机集群)、网络连接、CPU、磁盘驱动器或其他资源中分配负载,以达到优化资源使用、最大化吞吐率、最小化响应时间、同时避免过载的目的。
负载均衡优势:解决高并发,实现高可用,提供扩展性,提高安全性

常见的负载均衡的算法:
- 轮询
- 优点:服务器请求数目相同;
- 缺点:服务器压力不一样,不适合服务器配置不同的情况;
- 随机
- 优点:使用简单;
- 缺点:不适合机器配置不同的场景;
- 最少链接
- 优点:根据服务器当前的请求处理情况,动态分配;
- 缺点:算法实现相对复杂,需要监控服务器请求连接数;
- 源地址散列
- 优点:将来自同一IP地址的请求,同一会话期内,转发到相同的服务器;实现会话粘滞。
- 缺点:目标服务器宕机后,会话会丢失;
- 加权,在轮询,随机,最少链接,Hash等算法的基础上,通过加权的方式,进行负载服务器分配。
- 优点:根据权重,调节转发服务器的请求数目;
- 缺点:使用相对复杂;
常见的负载均衡方案:
- DNS负载均衡
- IP负载均衡
- 链路层负载均衡
- 混合型负载均衡
负载均衡的方案,一定要有健康检测和双机热备,一旦负载均衡的服务挂掉,会导致所有服务不可用。
(2) 正向代理和反向代理是什么?
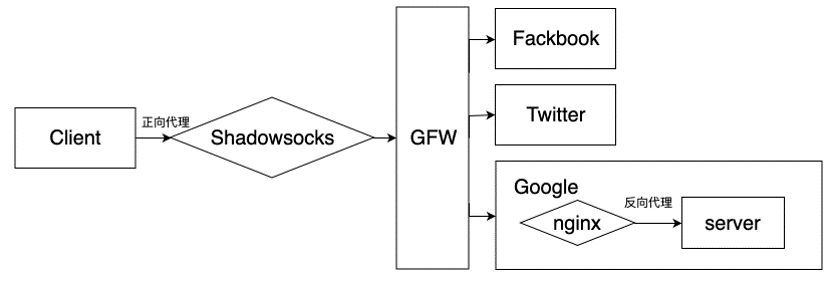
正向代理其实是客户端的代理,帮助客户端访问其无法访问的服务器资源。
反向代理则是服务器的代理,帮助服务器做负载均衡,安全防护等,反向代理是负载均衡常见的一种手段。
(3) 现阶段如何提高服务的QPS?
这个阶段,就可以考虑使用分布式集群来提高服务的QPS。
7. 分布式
我们继续带着两个问题来学习:
- 什么是分布式?
- 现阶段如何提高项目可维护性?
(1) 什么是分布式?
分布式系统是计算机程序的集合,这些程序利用跨多个独立计算节点的计算资源来实现共同的目标。它也被称为分布式计算或分布式数据库,并依靠不同的节点通过公共网络进行通信和同步。这些节点通常代表独立的物理硬件设备,但也可代表单独的软件进程或其他递归封装的系统。分布式系统旨在消除系统的瓶颈或中心故障点。
分布式计算系统具有如下特点:
资源共享 — 分布式系统可以共享硬件、软件或数据
并行处理 — 多台机器可以同时处理同一功能
支持扩展 — 当扩充到其他计算机时,计算和处理能力可以按需进行扩展
错误检测 — 可以更轻松地检测故障
公开透明 — 节点可以访问系统中的其他节点并与之通信
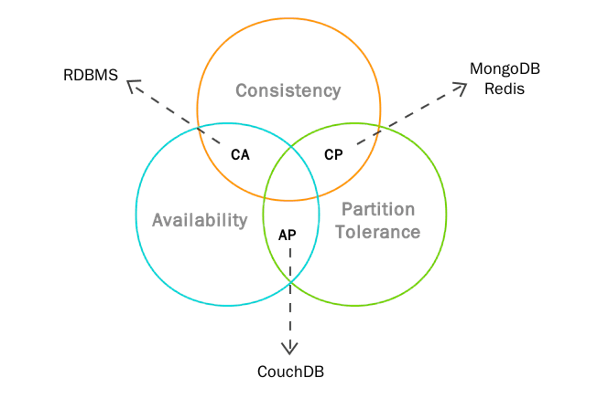
说到分布式系统就不得不提一下CAP原则。CAP原则又称CAP定理,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。
一致性 (Consistence): 等同于所有节点访问同一份最新的数据副本 (强一致性)
可用性 (Availability): 每次请求都能获取到非错的响应,但是不保证获取的数据为最新数据
分区容错性 (Partition tolerance): 系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,此时必须在 C 和 A 之间做出取舍
(2) 现阶段如何提高项目可维护性?
上面的更多的是讲技术层面的提升,现阶段想提升项目可维护性,就该进入一个新的阶段——业务拆分
8. 业务拆分
业务拆分简单来说就是把业务划分为一个个独立的业务模块,通过远程调用和消息队列等实现不同业务间的通信,通过Docker容器化技术更简单高效的实现业务的划分。
我们继续带着四个问题来学习:
- 远程调用是什么?
- 消息队列是什么?
- Docker是什么?
- 现阶段如何提高项目可维护性?
(1) 远程调用是什么?
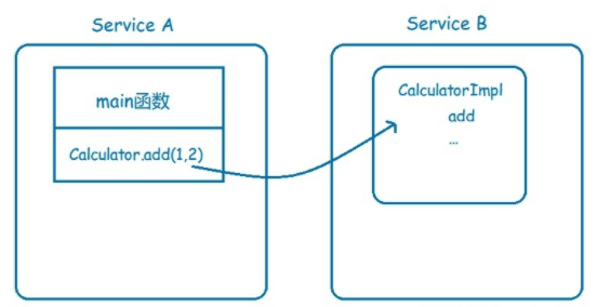
分布式计算中,远程过程调用(英语:Remote Procedure Call,RPC)是一个计算机通信协议。该协议允许运行于一台计算机的程序调用另一个地址空间(通常为一个开放网络的一台计算机)的子程序,而程序员就像调用本地程序一样,无需额外地为这个交互作用编程(无需关注细节)。RPC是一种服务器-客户端(Client/Server)模式,经典实现是一个通过发送请求-接收回应进行信息交互的系统。
远程过程调用RPC需要解决的问题:
Call ID映射
序列化和反序列化
网络传输
远程过程调用RPC和Restful Api的区别:RPC VS Restful => 面向过程 VS 面向资源
(2) 消息队列是什么?
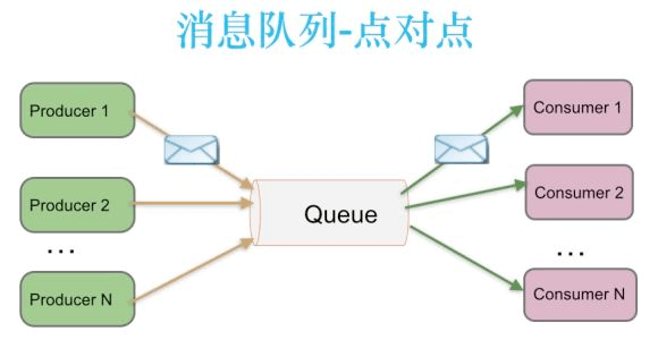
在计算机科学中,消息队列(英语:Message queue)是一种进程间通信或同一进程的不同线程间的通信方式,软件的队列用来处理一系列的输入,通常是来自用户。消息队列提供了异步的通信协议,每一个队列中的纪录包含详细说明的资料,包含发生的时间,输入设备的种类,以及特定的输入参数,也就是说:消息的发送者和接收者不需要同时与消息队列交互。消息会保存在队列中,直到接收者取回它。
消息队列的优势:
削峰填谷
降低耦合
消息队列的劣势:
- 系统可用性降低
- 系统复杂度提高
- 需要考虑一致性问题
发布-订阅模式是消息队列中常用的一种模式。
(3) Docker是什么?

Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的 Linux或Windows操作系统的机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。
Docker的优势:
- 多环境切换
- 持续集成
- 复杂环境一键构建
- 项目隔离
(4) 现阶段如何提高项目可维护性?
身为前端,怎么能忘了前后端分离这件事。
9. 前后端分离
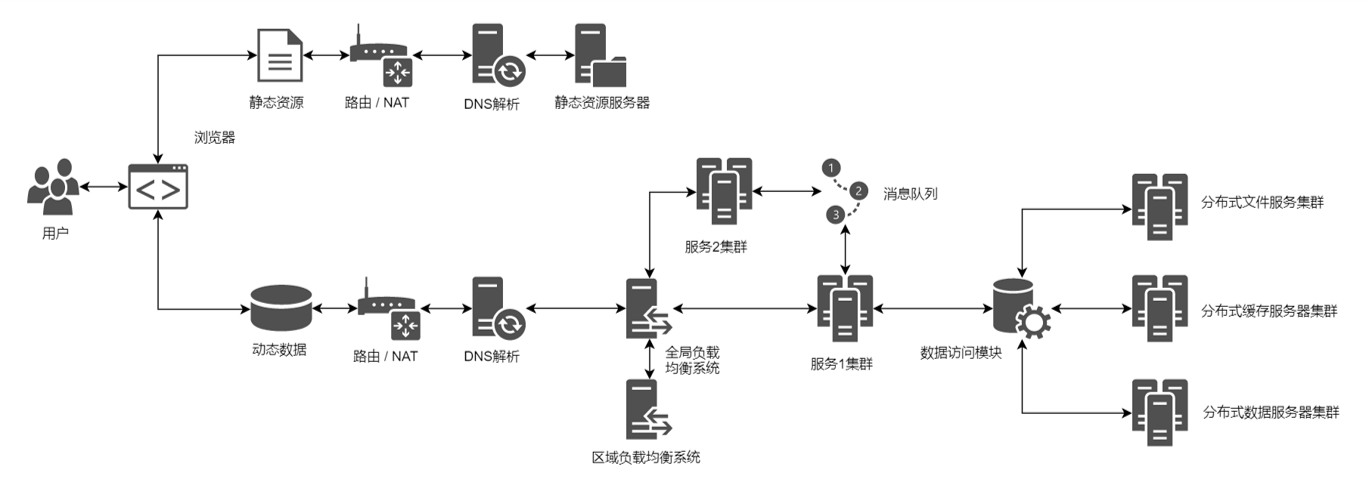
前后端分离前端开发就比较熟悉了,静态资源和动态请求分别放在不同的服务器上,可以进一步实现功能上的分离。
这个时候的问题:
- 现阶段如何提高不同地区用户访问速度?
(1) 现阶段如何提高不同地区用户访问速度
涉及到不同地区,那就该CDN登场了。
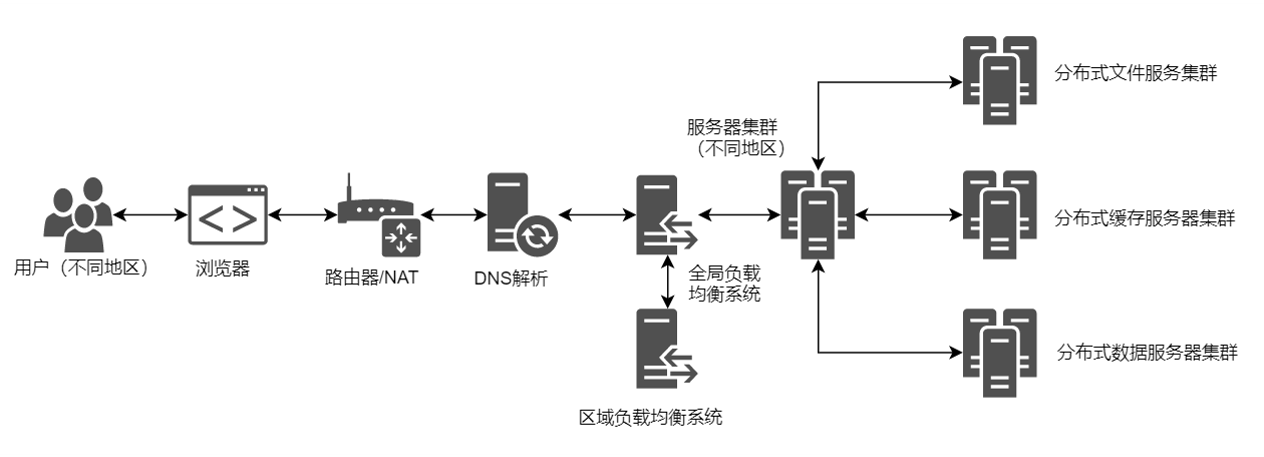
10. CDN
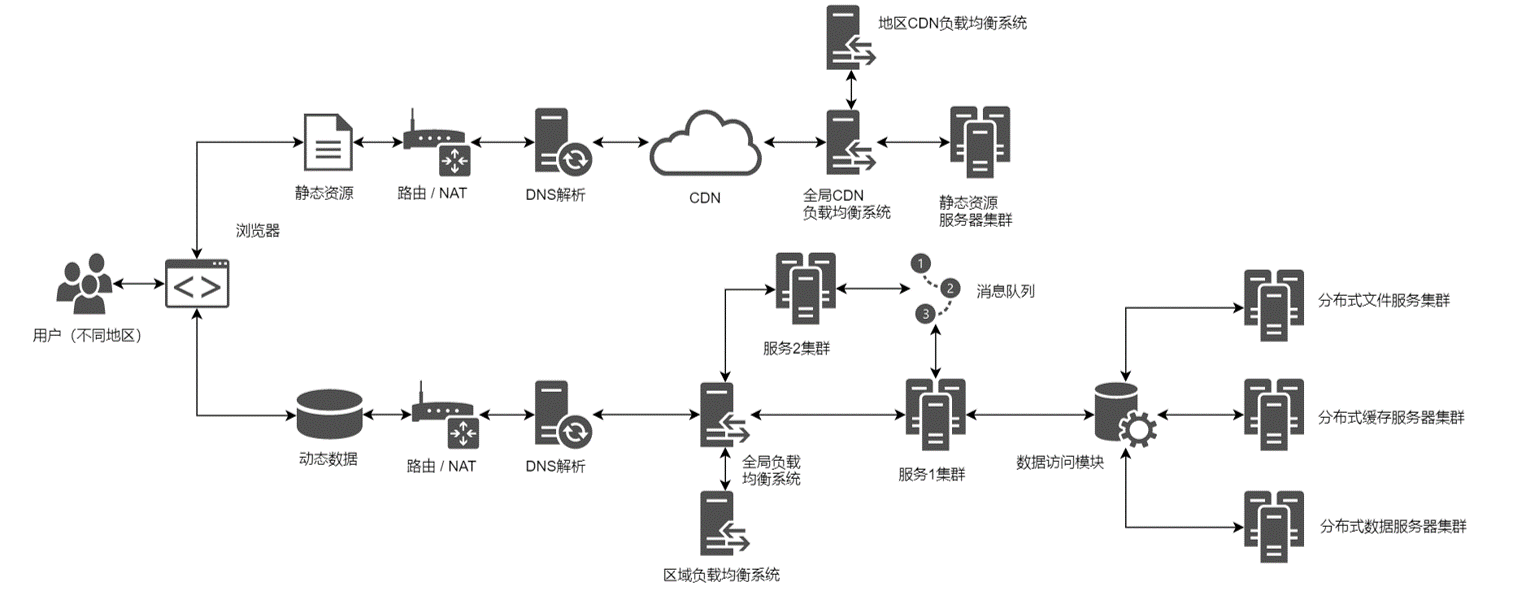
最后的问题:
- 什么是CDN?
(1) 什么是CDN?
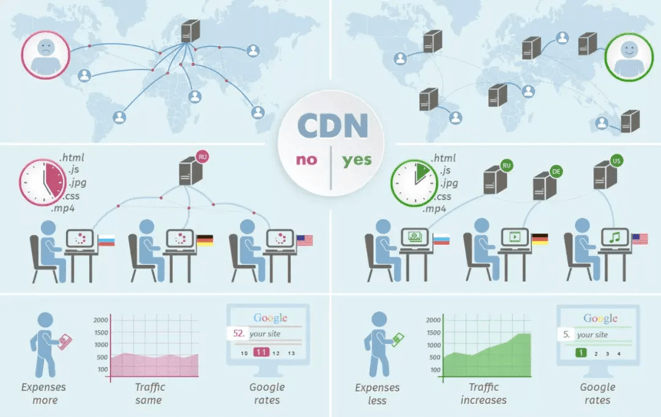
CDN(Content Delivery Network),内容分发网络。
简单理解,就类似于京东的仓储物流,对于不同地区的用户就近建立仓库,按照用户的地理位置,就近选择仓库发货。
CDN的DNS请求的过程:
输入URL
本地DNS解析
CNAME到CDN专用DNS服务器
CDN的全局负载均衡
CDN的区域负载均衡
最优的缓存服务器节点
IP地址返回给用户
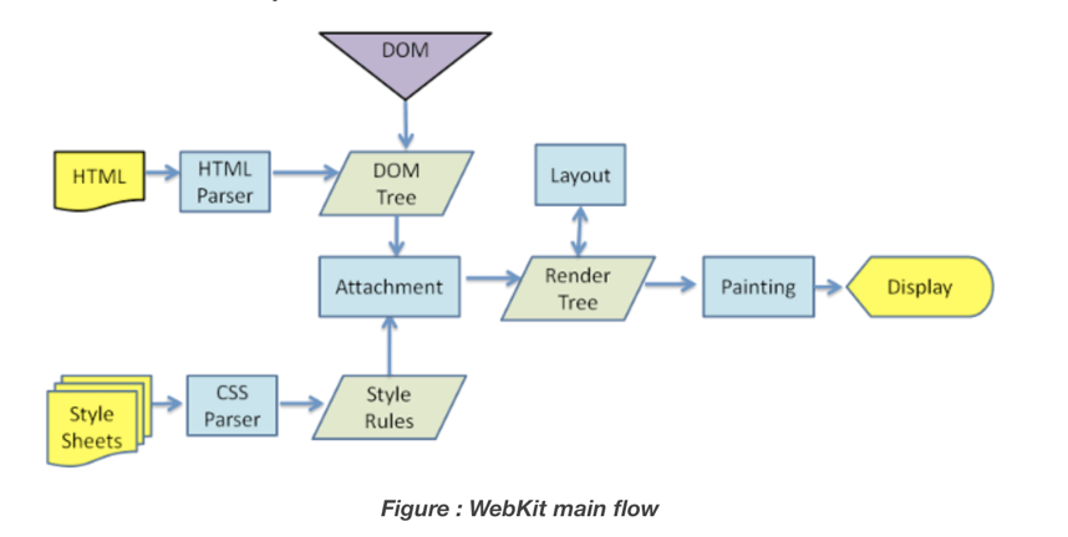
三、浏览器渲染
以一个URL的旅途,说完了现代Web服务架构的演进,最后一环,就是获取资源之后浏览器页面的渲染,这里就贴一张图来展示浏览器的渲染过程,不再赘述。